Apache Kafka具有称为“请求炼狱”的数据结构。炼狱将保留所有尚未满足其成功条件但还没有导致错误的请求。问题是“我们如何有效地跟踪集群中其他活动异步满足的成千上万个请求?”
Kafka实现了几种请求类型,这些请求类型无法立即通过响应进行响应。例子:
- 在所有同步副本都确认该写入之前,不能将
acks = all的生产请求视为已完成,如此我们可以保证,如果领导者失败,该请求也不会丢失。 - 直到至少有一个新字节的数据供消费者使用时,才会回答
min.bytes = 1的提取请求。这允许进行“长时间轮询”,以便用户不必忙于等待检查新数据的到来。
当(a)他们要求的条件完成或(b)发生某些超时时,这些请求被视为完成。
在任何时候,运行中的这些异步操作的数量与连接的数量成比例,对于卡夫卡而言,连接的数量通常为数万。
请求炼狱是为如此大规模的请求处理而设计的,但是旧的实现有许多缺陷。
在此博客中,我想解释旧实现的问题以及新实现如何解决它。我还将介绍基准测试结果。
Old Purgatory Design
请求炼狱由超时计时器和用于事件驱动处理的观察者列表的哈希图组成。当由于条件未满足而无法立即满足请求时,将请求放入炼狱。满足条件后,炼狱中的请求将在稍后完成,或者超过请求的timeout参数指定的时间后,被强制完成(超时)。在旧的设计中,它使用Java DelayQueue实现计时器。
请求完成后,不会立即从计时器或观察者列表中删除该请求。相反,将在条件检查期间删除发现的已完成请求。如果删除没有跟上,服务器可能耗尽JVM堆并导致OutOfMemoryError。
为了缓解这种情况,当炼狱中的请求数(未决或已完成)超过配置的数目时,称为收割者线程的单独线程将从炼狱中清除已完成的请求。清除操作将扫描计时器队列和所有观察者列表,以查找已完成的请求并将其删除。
通过将此配置参数timeout设置为低,服务器实际上可以避免内存问题。但是,如果服务器过于频繁地扫描所有列表,则必须付出重大的性能损失。
New Purgatory Design
新设计的目标是允许立即删除已完成的请求,并显著减少重要清除过程的负担。 它需要在计时器和请求中交叉引用条目。 另外,由于插入/删除操作是针对每个请求/完成发生的,因此强烈希望具有O(1) 插入/删除成本。
为了满足这些要求,我们设计了一种基于 Hierarchical Timing Wheels [1]. 的新炼狱实现。
Hierarchical Timing Wheel
一个简单的计时轮是一系列计时任务的循环列表。让u成为时间单位。大小为 n 的计时轮有 n 个存储桶,可以在 个时间间隔内保存计时器任务。每个存储桶都包含属于相应时间范围的计时器任务。首先,第一个存储桶保存 的任务,第二个存储桶保存 , … 的任务,第 n 个存储桶 。在时间单位u的每个间隔中,计时器都会计时并移动到下一个存储桶,然后使其中的所有计时器任务到期。因此,计时器永远不会在当前时间将任务插入存储桶中,因为它已经过期。计时器立即运行过期的任务。然后清空的存储桶可用于下一个回合,因此如果当前存储桶的时间为t,则在滴答之后它将成为 的存储桶。计时轮的插入/删除(开始计时器/停止计时器)成本为O(1),而基于优先级队列的计时器(例如java.util.concurrent.DelayQueue 和 java.util.Timer)的成本为 O(log n)插入/删除消耗。请注意,DelayQueue 或 Timer都不支持随机删除。
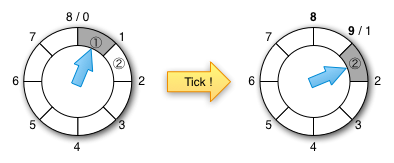
简单计时轮的主要缺点在于,它假定计时器请求在距当前时间 的时间间隔内。如果计时器请求超出此时间间隔,则为溢出。分层的定时轮处理此类溢出。它是按层次结构组织的定时轮,将溢出委托给上一级轮。最低级别具有最佳时间分辨率。随着我们向上移动层次结构,时间分辨率变得更粗糙。如果时间轮在一个级别上的分辨率为 u 并且大小为 n,则第二个级别的分辨率应为 ,第三个级别的分辨率应为 ,依此类推。在每个级别上,溢出都被委托给更高一级的时间轮。当较高级别的时间轮滴答作响时,它将计时器任务重新插入较低级别。可以按需创建溢流轮。当溢出存储桶中的存储桶到期时,该存储桶中的所有任务都将递归地重新插入到计时器中。然后将任务移至更细的时间轮(finer grain wheels)或执行任务。插入(启动计时器)成本为O(m),其中 m 是时间轮的数量,与系统中的请求数量相比通常很小,而删除(停止计时器)成本仍为O(1)。
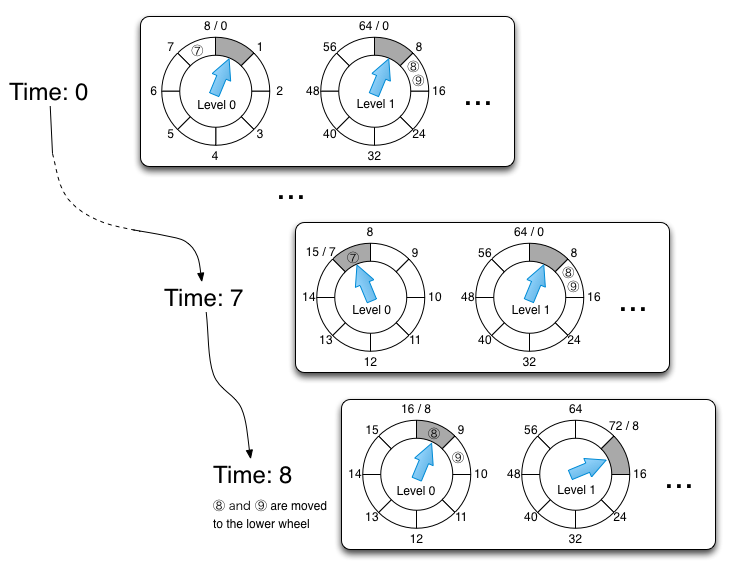
Doubly Linked List for Buckets in Timing Wheels
在新设计中,我们对计时轮中的桶使用自己的双向链表实现。 双链列表的优点是,如果我们在列表中有访问链表单元的能力,则它允许O(1)插入/删除列表项。
排队到计时器队列时,计时器任务实例将自身保存链表单元。 任务完成或取消后,将使用任务本身中保存的链表单元更新列表。
Driving Clock using DelayQueue
一个简单的实现可以使用一个线程,该线程每单位时间唤醒一次并执行轮转,轮转会检查存储桶中是否有任何任务。 炼狱的单位时间为1毫秒(u = 1毫秒)。 如果最低级别的请求稀少,这可能是浪费的。 通常是这种情况,因为大多数请求在插入最低级别的时间轮之前就已得到满足。 如果线程仅在有非空存储桶到期时才唤醒,这将是很好的。 新炼狱使用类似于旧实现的方式使用 java.util.concurrent.DelayQueue 来执行此操作,但是我们将任务存储区入队,而不是将单个任务加入队列。 这种设计具有性能优势。 DelayQueue 中的项目数由存储桶数限制,通常比任务数小得多,因此,对 DelayQueue 内部的优先级队列的报价/轮询操作数将大大减少。
Purging Watcher Lists
在旧的实现中,监视者列表的清除操作由监视者列表的总大小触发。问题在于,即使没有太多清除请求,观察者列表也可能超过阈值。发生这种情况时,会大大增加CPU负载。理想情况下,清除操作应由观察者列出的已完成请求数触发。
在新设计中,将立即以O(1)成本将完成的请求从计时器队列中删除。这意味着计时器队列中的请求数就是在任何时候的未决请求数。因此,如果我们知道炼狱中不同请求的总数,包括未决请求数和已完成但仍受监视的请求数之和,则可以避免不必要的清除操作。跟踪炼狱中不同请求的确切数量并非易事,因为可能会或可能不会看到请求。在新设计中,我们估计炼狱中的请求总数,而不是尝试保持确切的数目。
请求的估计数量保持如下。
- 每当观察到新请求时,估计的请求总数E都会增加。
- 在开始清除操作之前,我们将估计的请求总数重置为计时器队列的大小。这是当前待处理的请求数。如果在清除期间没有向炼狱添加任何请求,则E是清除后正确的请求数。
- 如果在清除期间向炼狱添加了一些请求,则E递增为E+新监视的请求数。这可能是一个高估,因为在清除操作期间,某些新请求可能已完成,并已从观察者列表中删除。我们期望被高估的机会和被高估的机会很小。
Benchmark
我们比较了两个炼狱实现,旧实现和新实现的入队性能。这是一个微观基准。它仅测量炼狱入队表现。炼狱与系统的其余部分分离,并且还使用了虚假请求,没有任何用处。因此,在实际系统中炼狱的吞吐量可能低于测试所示的数量。
在测试中,假设请求的间隔遵循指数分布。每个请求都需要一个从对数正态分布中得出的时间。通过调整对数正态分布的形状,我们可以测试不同的超时率。
刻度大小为1ms,转轮大小为20。超时设置为200ms。请求的数据大小为100字节。对于低超时率情况,我们选择75percentile = 60ms和50percentile =20。对于高超时率情况,我们选择75percentile = 400ms和50percentile = 200ms。每次运行总共排队一百万个请求。
请求由单独的线程主动完成。本应在超时之前完成的请求会排队到另一个 DelayQueue 中。并且有一个单独的线程保持轮询并完成它们。不能保证实际完成时间的准确性。
JVM堆大小设置为200m,以重现内存不足的情况。
结果表明,在高入队率区域中存在巨大差异。随着目标速率的提高,这两种实现方式最初都跟上了请求。但是,在低超时情况下,旧实现的饱和度约为40000 RPS(每秒请求数),而新实现则未表现出任何明显的性能下降,而在高超时场景中,旧实现的饱和度约为25000 RPS,而新实现在此基准测试中,实施达到了105000 RPS。
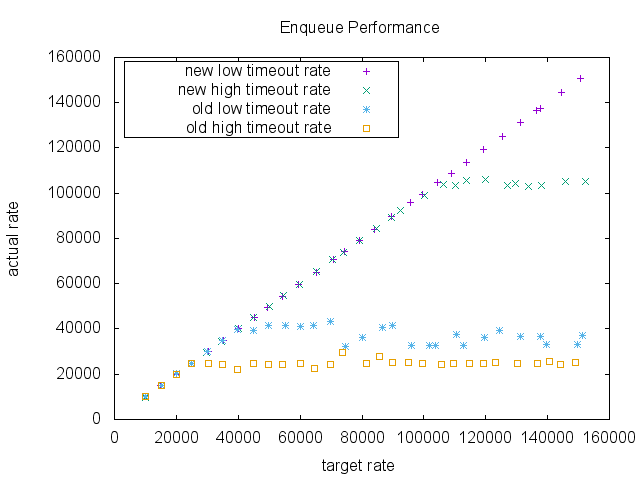
此外,在新的实现中,CPU使用率明显更好。 请注意,由于其可扩展性限制,旧版实现的数据点不高于〜40000 RPS。 还要注意,在新实现中它的CPU时间稳定增长的同时,它的CPU时间大约为1.2。 它表明旧的实现可能由于同步而遇到了并发问题。
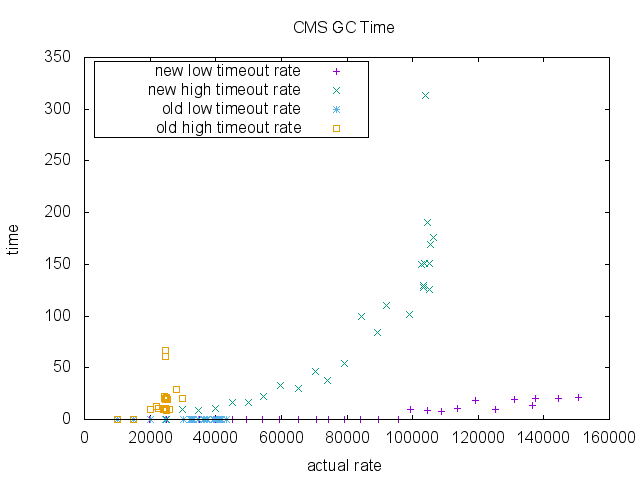
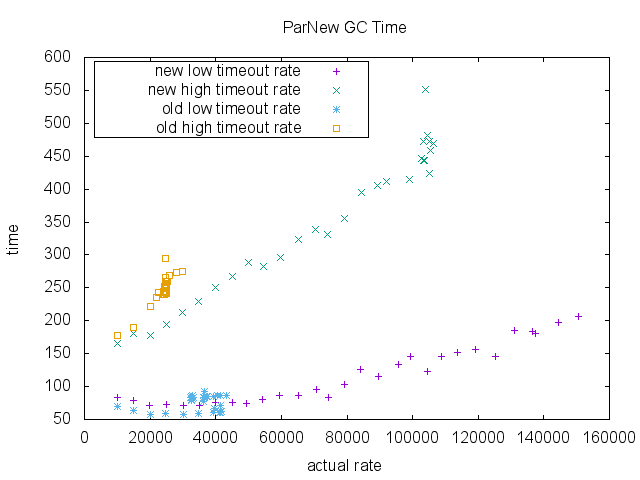
最后,我们测量了ParNew收集和CMS收集的总GC时间(毫秒)。 在旧的实施方式和新的实施方式之间,在旧的实施方式可以维持的入队率方面没有太大差异。 再次注意,由于其可扩展性限制,旧的实现的数据点不高于〜40000 RPS。
Summary
在新设计中,我们将分层定时轮用于超时定时器,并使用定时器桶的 DelayQueue 来按需提前时钟。 立即将完成的请求从计时器队列中删除,费用为O(1)。 这些存储桶保留在延迟队列中,但是,存储桶的数量是有限制的。 而且,在运行正常的系统中,大多数请求在超时之前就已得到满足,并且许多存储桶在拉出延迟队列之前就变空了。 因此,计时器应该很少具有较低间隔的时段。 这种设计的优点是计时器队列中的请求数就是在任何时候的待处理请求数。 这使我们能够估计需要清除的请求数。 我们可以避免对观察者列表进行不必要的清除操作。 结果,我们在请求率方面实现了更高的可伸缩性,并具有更好的CPU使用率。
References
Apache Kafka, Purgatory, and Hierarchical Timing Wheels