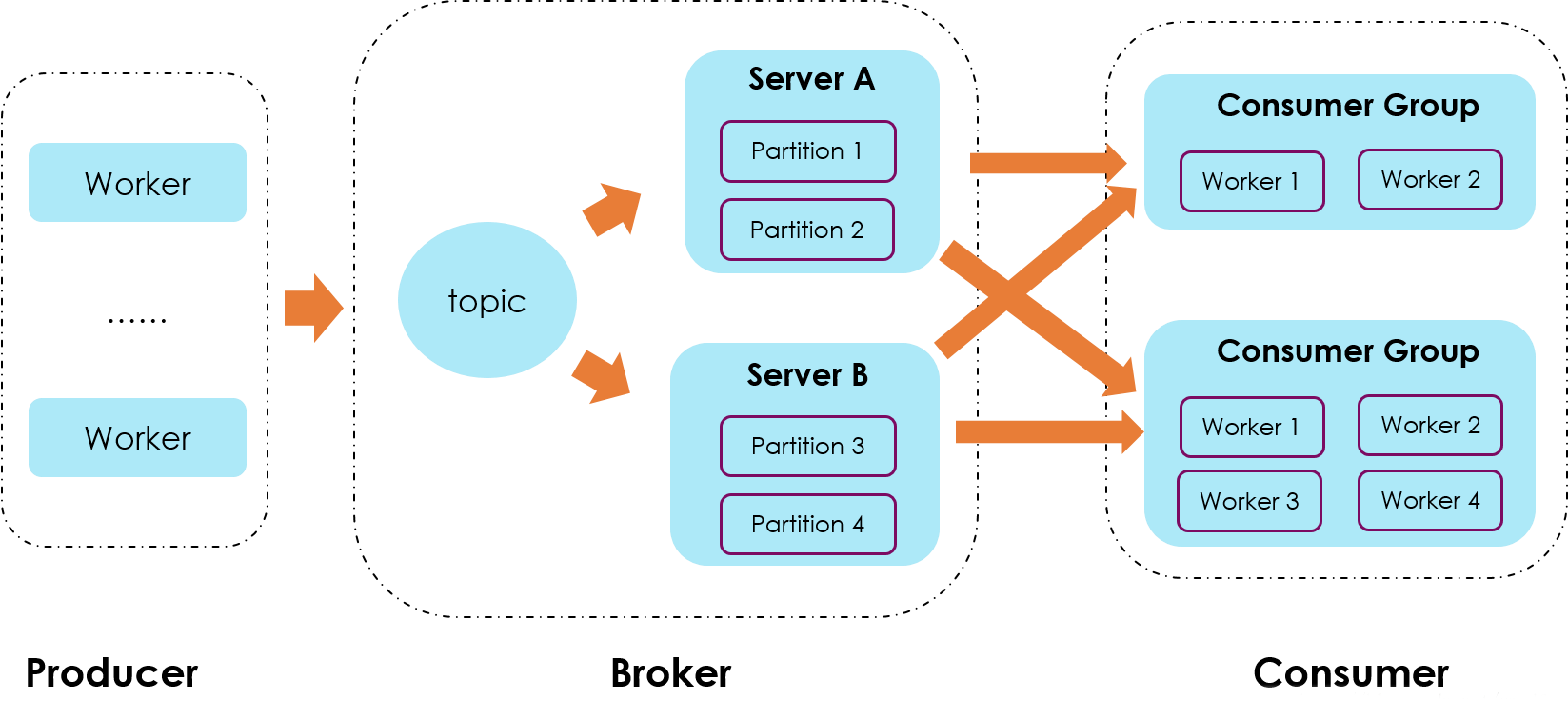
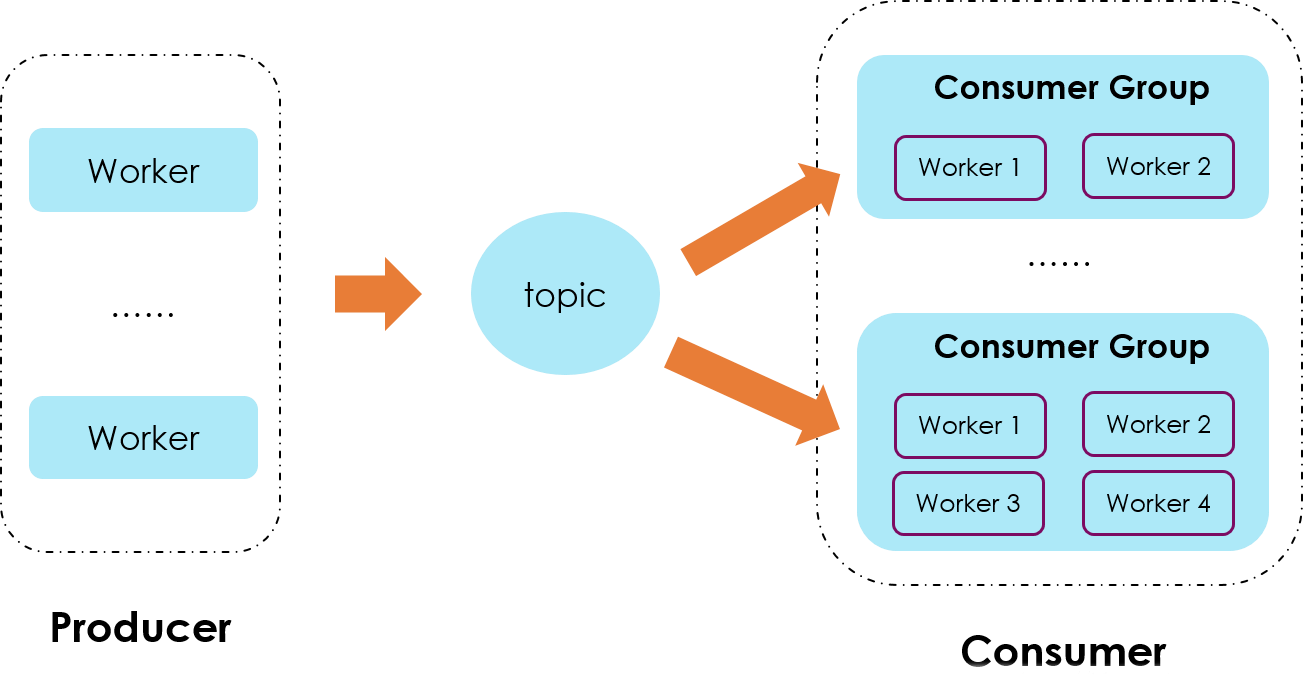
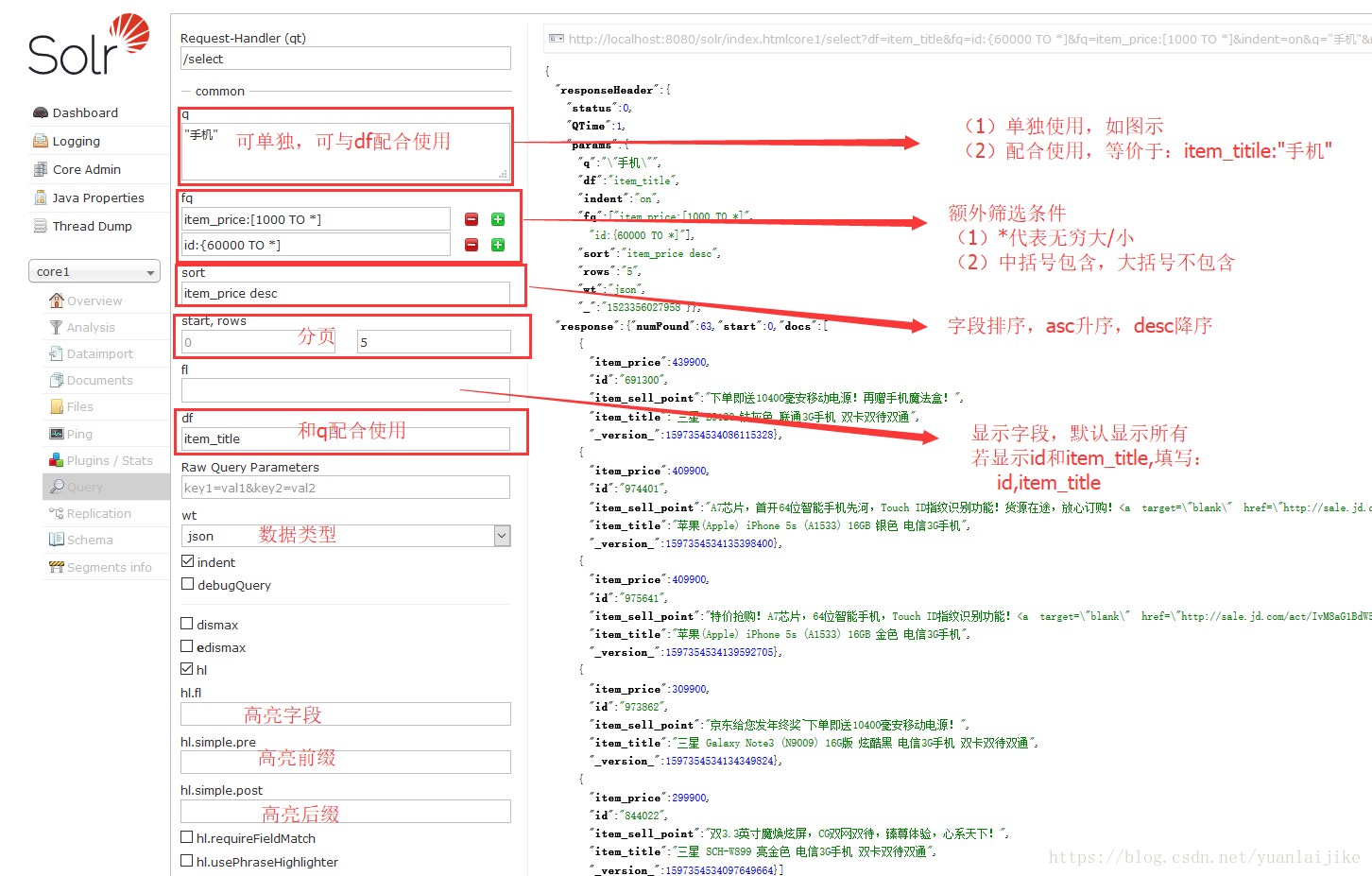
install nginx in aws linux
1 | sudo amazon-linux-extras install nginx1.12 |
apply certificate
apply in wanwang.aliyun.com
wait a few minutes, download nginx version certificate package
config nginx
in /etc/nginx/nginx.conf
add server configuration
1 | server { |
start nginx
1 | // check config file |
some useful command1
2
3
4
5// start in manual
sudo /usr/sbin/nginx -c /etc/nginx/nginx.conf
sudo service nginx stop // stop
sudo service nginx start // start
sudo service nginx restart // restart