前言
被 Baguette 毒到,看教程视频打算自己设计一个来玩。
事实证明,从零开始自制没这么简单,天马行空的胡乱摆弄一番后便放弃了。
之后还是把【LY092-MINI】复刻出真无线蓝牙版本的想法激发了我,让我有足够动力。
期间碰到相当多困难,一度让我想放弃,还好坚持了下来。
虽然最后的完成度不够高,但已经让我满意,成就感满满。
因为左右各有44个键共88个,就管它叫 ERGO88 吧。
最佳的期望是能拥有【LY092-MINI】布局的分体无线键盘,要有层功能、宏功能。
要能在保持尺寸不变、降低高度同时,有不错的可用性、可靠性,最好还能有不错的外观。
从淘宝找到闲鱼,再到zFrontier,各种客制化群,发现分体键盘是个较小众的产品品类。
分体键盘普遍都是有线键盘,无线分体键盘要么是左右有连线,要么是键位学习成本很高只能当玩具。
其中的2.4G接收器方案是个比较实用的方案,在稳定可靠上有优势,缺点是需要接收器没法用蓝牙、USB。
Github里的老哥收集了一堆分体,可惜没有能满足我需求的分体。
https://github.com/diimdeep/awesome-split-keyboards
这个站点也很不错,有很多小众键盘鼠标介绍。
http://xahlee.info/kbd/ergonomic_keyboards_index.html
大拇指键盘【LY092-MINI】年初渐渐有几个轴出现不触发或要多次按键才触发的问题。
想想大概是凯华轴的寿命到了,买了Cherry的五脚红轴替换坏掉的和部分使用频率高的键位。1
2E R T A G
U I O L N
字母频率可以参考
https://en.wikipedia.org/wiki/Letter_frequency
焊接轴的替换需要克服吸锡的烦恼。
诀窍是别怕烙铁烫坏吸锡器尽量靠近焊点,
在焊点熔融的时候吸锡动作要快迅速怼在焊点上,避免锡吸不干净残留在焊盘上。
焊点如果多次熔融,可能会出现活性下降不融化的情况,
或是锡没吸干净针脚依然和焊盘粘连,这些都可以补锡解决。
老伙计又复活了,开始觉得换轴很有意思。
开始了解更多的键盘,更多的触发开关形式。
learn on project springboot-learning-example1
git clone https://github.com/JeffLi1993/springboot-learning-example.git
copy module springboot-mybatis-redis to springboot-redis
modify pom.xml, remove mybatis/mysql, add lombok
1 | <?xml version="1.0" encoding="UTF-8"?> |
今天开始,打算写一系列有关日语的随笔。不定期更新。这些内容一般不会在任何教科书里提到,考试当然也不会考到。所以,主要是我个人的研究爱好了。这系列的文章,主要是从日语的发展角度来对现在的一些常用词作出解释,从某种角度来说,我认为这也可以帮助学习日语的人来加深理解,起到一定的提高作用。
大多数内容都是基础的,有一点日语基础的人应该都可以阅读。
日语里分音读和训读。汉字作音读的时候,其发音和中文类似,这一点对于学习日语的中国人来说,是比较方便的。
但是,有一些汉字,音读的发音和中文的发音还是有不少区别的,我们有时候会很气恼,为什么日本人偏要把我们的发音改掉呢,好好地发成一样不是很好吗?教科书的解释,一般是说,日语的音读是采用了中国的古音,所以和现代的汉语有差距。
很多情况下的确如此,但也并不全是这样。比如“海”字。中文发“Hai”(はい),日语发“Kai”(かい),但是,并不是说这个字在中国古代发作Kai,后来变成Hai。事实上,“海”这个字,中国历史上从来没有发作Kai过。即使不发Hai,也是He,或者Hei,总而言之,和“K”是没有关系的。
那么日本人引进这个字的时候,为什么不用はい作为读音,而用かい呢?答案很简单,在日本古代,は这个假名不发音为Ha,而是发音为Pa。
在室町以前,はひふへほ的发音,是Pa,Pi,Pu,Pe,Po。而日语里面,没有Ha这个音。于是,对于“海”这个字的注音,只能在比较接近的Kai,Gai,Pai中挑选,显然,Kai的发音更为接近。
同样的原因,所有中文里以H为声母的汉字,到了日本后,发音全变成了か行,当然有一些因为浊化而成为が行。除了“海”,其他的例子还有“好”、“浩”、“号”等字,中文发音为Hao,日语音读为こう(Kou)或者ごう(Gou);贺,中文发音为He,日语发音则为か(Ka);黑,中文发音为Hei,日语发音则为こく(Koku)等等,大家可以自己再找许多例子出来,这里不多写了。
但是,有人可能要问,如果は行全变成了か行,那么日语中不是就不存在Hai的音读了吗?当然不是。这一点,我们下一期再说吧。
Apache Kafka具有称为“请求炼狱”的数据结构。炼狱将保留所有尚未满足其成功条件但还没有导致错误的请求。问题是“我们如何有效地跟踪集群中其他活动异步满足的成千上万个请求?”
Kafka实现了几种请求类型,这些请求类型无法立即通过响应进行响应。例子:
acks = all的生产请求视为已完成,如此我们可以保证,如果领导者失败,该请求也不会丢失。min.bytes = 1的提取请求。这允许进行“长时间轮询”,以便用户不必忙于等待检查新数据的到来。当(a)他们要求的条件完成或(b)发生某些超时时,这些请求被视为完成。
在任何时候,运行中的这些异步操作的数量与连接的数量成比例,对于卡夫卡而言,连接的数量通常为数万。
请求炼狱是为如此大规模的请求处理而设计的,但是旧的实现有许多缺陷。
在此博客中,我想解释旧实现的问题以及新实现如何解决它。我还将介绍基准测试结果。
https://kafka-tutorials.confluent.io/kafka-console-consumer-producer-basics/kafka.html
i saw confluent.io‘s code block is great.
it have feature like clipboard/ collapsible, even font looke good.
so i want add clipboard function to my blog at first.
at first i search by markdown code block copy, but no article helps.
then i search by hexo next theme code block, finally find the article i want.
单线程的Redis为什么如此快?
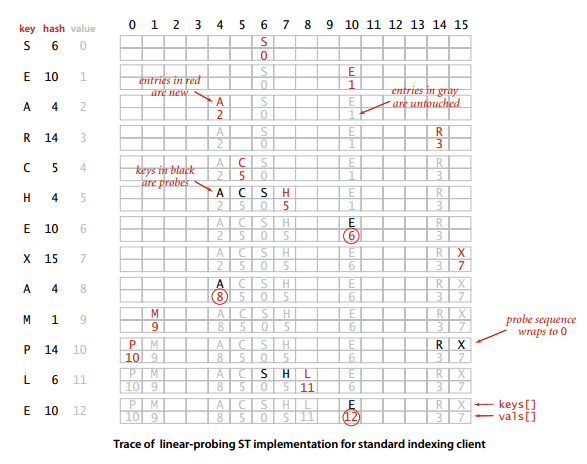
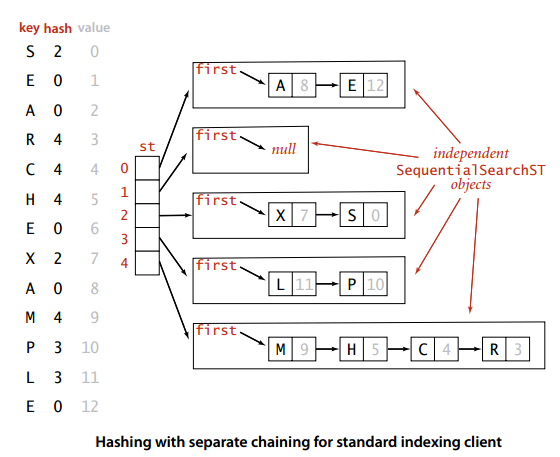
看到Redis高性能的原因里,有IO多路复用一项,感到非常好奇具体是怎么实现的呢。
网上浏览了一圈,代码探索了一遍,发现复用发生在系统内核。
软件层面通过系统函数库epoll 、 iocp,把IO组织起来,我大致是这样理解的。
在之前写 探索redis 键散列过程源码 文章时,看到redis有用到事件机制。
这回,在查Redis多路复用时,也看到了这个机制,决定将事件粗略探索一下,范围就定在“文件事件”上。
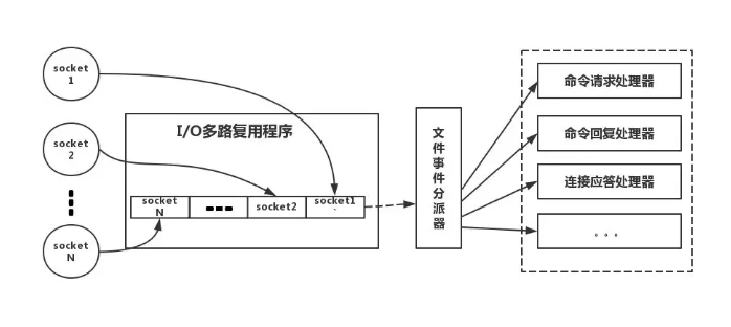
multiplexing监听多个套接字,根据行为的不同关联不同事件处理器accept, read, write, close等操作时,会产生相对应的事件,触发事先关联的事件处理器(ps. 回调函数)处理